
Ingin memahami rumus Naive Bayes, alur algoritma, dan contoh perhitungannya dengan mudah? Naive Bayes adalah algoritma machine learning yang digunakan untuk klasifikasi data berdasarkan probabilitas dari Teorema Bayes, dan sering digunakan dalam data mining karena sederhana namun efektif.
Pada artikel ini, kamu akan mempelajari secara lengkap bagaimana cara kerja algoritma Naive Bayes, mulai dari rumus dasar, alur perhitungan, hingga contoh kasus menggunakan data diskrit dan kontinu. Dengan memahami konsep ini, kamu bisa lebih mudah mengaplikasikan Naive Bayes dalam berbagai kasus seperti klasifikasi data, prediksi, hingga analisis keputusan.

Rumus dan Alur Algoritma Naive Bayes
Untuk bisa lebih memahami algoritma ini, berikut rumus umum Teorema Bayes yang menjadi dasar Naive bayes.
Keterangan:
- : sampel data dengan kelas tidak diketahui
- : hipotesis bahwa adalah kelas tertentu
- : probabilitas prior dari kelas
- : probabilitas evidence dari sampel
- : likelihood data pada kelas
Alur Naive Bayes menurut artikel Anda:
- Hitung peluang kasus baru untuk setiap hipotesis kelas .
- Hitung akumulasi peluang likelihood .
- Hitung .
- Tentukan kelas dengan nilai tertinggi.
Namun, jika atribut ke- bersifat kontinu, maka nilai probabilitas tidak dihitung dengan frekuensi, melainkan diestimasi menggunakan fungsi densitas probabilitas Gaussian (Distribusi Normal) sebagai berikut:
Keterangan:
- = nilai atribut kontinu ke-
- = nilai rata-rata (mean) atribut pada kelas
- = simpangan baku (standar deviasi) atribut pada kelas
Rumus Teorema Bayes diatas tadi menjelaskan bahwa peluang masuknya sampel karakteristik tertentu dalam class C (posterior) adalah peluang munculnya kelas C ( sebelum masuknya sampel tersebut, sering kali disebut prior), dikali dengan peluang kemunculan karakteristik-karakteristik sampel pada class C (disebut juga likelihood) kemudian dibagi dengan peluang kemunculan karakteristik sampel secara global (disebut juga evidence). Oleh karena itu rumus dapat pula ditulis sebagai berikut.
Nilai evidence selalu tetap untuk setiap class pada satu sampel. Nilai dari posterior tersebut nantinya akan dibandingkan dengan nilai posterior class lainnya untuk menentukan class apa suatu sampel akan diklasifikasikan.
Baca Juga: Naive Bayes Adalah: Pengertian, Tujuan dan Penerapannya
Contoh Soal Data Diskrit
Berikut ini adalah contoh perhitungan naive bayes dengan menggunakan data diskrit.
Untuk menentukan suatu daerah akan dipilih sebagai lokasi untuk mendirikan perumahan dan telah dihimpun 10 aturan (data). Ada 4 atribut yang akan digunakan yaitu.
- Harga tanah per meter persegi (C1).
- Jarak daerah tersebut dari pusat kota (C2).
- Ada atau tidaknya angkutan umum di daerah tersebut (C3).
- Keputusan untuk memilih daerah tersebut sebagai lokasi perumahan (C4).
Dengan soal, suatu daerah dengan harga tanah mahal, jarak dari pusat kota sedang dan ada angkutan umum. Maka tentukan apakah daerah tersebut dipilih untuk mendirikan perumahan?
| Aturan ke- | Harga tanah (C1) | Jarak dari pusat kota (C2) | Ada angkutan umum (C3) | Dipilih untuk Perumahan (C4) |
|---|---|---|---|---|
| 1 | Murah | Dekat | Tidak | Iya |
| 2 | Sedang | Dekat | Tidak | Iya |
| 3 | Mahal | Dekat | Tidak | Iya |
| 4 | Mahal | Jauh | Tidak | Tidak |
| 5 | Mahal | Sedang | Tidak | Tidak |
| 6 | Sedang | Jauh | Ada | Tidak |
| 7 | Murah | Jauh | Ada | Tidak |
| 8 | Murah | Sedang | Tidak | Iya |
| 9 | Mahal | Jauh | Ada | Tidak |
| 10 | Sedang | Sedang | Ada | Iya |
Hal yang pertama kamu lakukan adalah mencari probabilitas kemunculan setiap nilai untuk atribut (class).
- Probabilitas kemunculan setiap nilai untuk atribut Harga tanah (C1).
| Harga tanah | Jumlah kejadian ‘dipilih’ Iya | Jumlah kejadian ‘dipilih’ Tidak | Probabilitas Iya | Probabilitas Tidak |
|---|---|---|---|---|
| Murah | 2 | 1 | 2/5 | 1/5 |
| Sedang | 2 | 1 | 2/5 | 1/5 |
| Mahal | 1 | 3 | 1/5 | 3/5 |
| Jumlah | 5 | 5 | 1 | 1 |
- Probabilitas kemunculan setiap nilai untuk atribut Jarak dari pusat kota (C2).
| Jarak dari pusat kota | Jumlah kejadian ‘dipilih’ Iya | Jumlah kejadian ‘dipilih’ Tidak | Probabilitas Iya | Probabilitas Tidak |
|---|---|---|---|---|
| Dekat | 3 | 0 | 3/5 | 0 |
| Sedang | 2 | 1 | 2/5 | 1/5 |
| Jauh | 0 | 4 | 0/5 | 4/5 |
| Jumlah | 5 | 5 | 1 | 1 |
- Probabilitas kemunculan setiap nilai untuk atribut Ada angkutan umum (C3).
| Ada angkutan umum | Jumlah kejadian ‘dipilih’ Iya | Jumlah kejadian ‘dipilih’ Tidak | Probabilitas Iya | Probabilitas Tidak |
|---|---|---|---|---|
| Ada | 1 | 3 | 1/5 | 3/5 |
| Tidak | 4 | 2 | 4/5 | 2/5 |
| Jumlah | 5 | 5 | 1 | 1 |
- Probabilitas kemunculan setiap nilai untuk atribut Dipilih untuk perumahan (C4)
| Dipilih untuk perumahan | Jumlah kejadian ‘dipilih’ Iya | Jumlah kejadian ‘dipilih’ Tidak | Probabilitas Iya | Probabilitas Tidak |
|---|---|---|---|---|
| Jumlah | 5 | 5 | 1/2 | 1/2 |
Berdasarkan data tersebut, apabila diketahui suatu daerah dengan harga tanah mahal, jarak dari pusat kota sedang dan ada angkutan umum, maka dapat dihitung:
Likelihood untuk Iya:
Likelihood untuk Tidak:
Nilai probabilitas dapat dihitung dengan melakukan normalisasi terhadap likelihood tersebut sehingga jumlah nilai yang diperoleh = 1.
Normalisasi menjadi probabilitas:
Kesimpulan: Karena , maka daerah tersebut tidak dipilih untuk perumahan.
Baca Juga: Belajar Kecerdasan Buatan (AI): Sejarah Kecerdasan Buatan
Contoh Data Kontinu
Berikut ini kita akan lanjut dengan contoh perhitungan naive bayes menggunakan data kontinu.
Contoh untuk data kontinu kita adaptasi dari soal sebelumnya. Apabila C1 = 300, C2 = 17, C3 = Tidak, maka tentunkan apakah lokasi akan di bangun perumahan?
| Aturan ke- | Harga tanah (C1) | Jarak dari pusat kota (C2) | Ada angkutan umum (C3) | Dipilih untuk Perumahan (C4) |
|---|---|---|---|---|
| 1 | 100 | 2 | Tidak | Iya |
| 2 | 200 | 1 | Tidak | Iya |
| 3 | 500 | 3 | Tidak | Iya |
| 4 | 600 | 20 | Tidak | Tidak |
| 5 | 550 | 8 | Tidak | Tidak |
| 6 | 250 | 25 | Ada | Tidak |
| 7 | 75 | 15 | Ada | Tidak |
| 8 | 80 | 10 | Tidak | Iya |
| 9 | 700 | 18 | Ada | Tidak |
| 10 | 180 | 8 | Ada | Iya |
Hal yang pertama kamu lakukan adalah mencari probabilitas kemunculan setiap nilai untuk atribut (class).
- Probabilitas kemunculan setiap nilai untuk atribut Harga tanah (C1).
| Iya | Tidak | |
|---|---|---|
| 1 | 100 | 600 |
| 2 | 200 | 550 |
| 3 | 500 | 250 |
| 4 | 80 | 75 |
| 5 | 180 | 700 |
| Mean | 212 | 435 |
| Deviasi standar | 168,8787 | 261,9637 |
- Probabilitas kemunculan setiap nilai untuk atribut Jarak dari pusat kota (C2).
| Iya | Tidak | |
|---|---|---|
| 1 | 2 | 20 |
| 2 | 1 | 8 |
| 3 | 3 | 25 |
| 4 | 10 | 15 |
| 5 | 8 | 18 |
| Mean | 4,8 | 17,2 |
| Deviasi standar | 3,9623 | 6,3008 |
Untuk data yang diskrit kita ambil lansung nilainya dari tabel contoh soal perhitungan naive bayes dengan data diskrit supaya tidak berlama-lama. Berdasarkan hasil dari perhitungan dan soal tersebut, maka:
Ketika nilai C1 dan C2 sudah dapat dengan rumus Gaussian, jadi kita lanjut untuk mencari nilai likelihood.
Nilai probabilitas dapat dihitung dengan melakukan normalisasi terhadap likelihood tersebut sehingga jumlah nilai yang diperoleh = 1.
Maka dari hasil akhir kita dapat menyimpulkan bahwa pada lokasi tersebut tidak dibangun perumahan.
Baca Juga: Belajar Kecerdasan Buatan (AI): 15 Contoh Kecerdasan Buatan Dalam Kehidupan Sehari-hari
Penutup
Nah, sekarang kamu sudah lebih paham mengenai algoritma naive bayes. Kamu sudah mengerti bagaimana alur dan proses perhitungan yang terjadi di algoritma naive bayes.
Artikel ini merupakan bagian dari seri Kecerdasan Buatan KantinIT.com. Jika artikel ini bermanfaat, jangan lupa bagikan ke media sosial atau ke teman kamu.
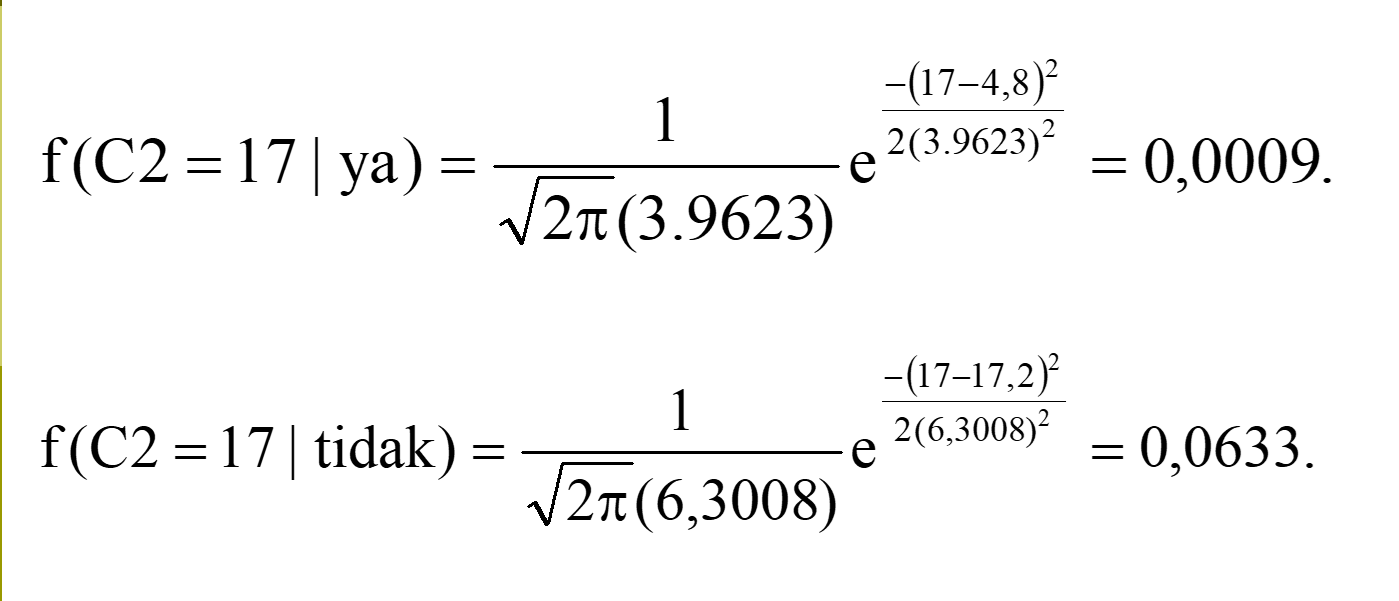{kind=link}