Dalam dunia data mining dan machine learning, memahami performa model adalah langkah krusial sebelum model digunakan di dunia nyata. Salah satu metode evaluasi yang paling sering digunakan adalah Confusion Matrix, yaitu teknik yang digunakan untuk mengukur seberapa akurat model dalam memprediksi label data. Tanpa evaluasi yang tepat, model yang terlihat “bagus” bisa saja sebenarnya menghasilkan banyak kesalahan yang tidak disadari.
Lalu sebenarnya, apa itu Confusion Matrix dan bagaimana cara kerjanya? Pada artikel ini, kita akan membahas secara lengkap mulai dari pengertian, komponen utama seperti True Positive hingga False Negative, hingga cara menghitung metrik penting seperti accuracy, precision, recall, dan F1-score. Dengan memahami konsep ini, kamu tidak hanya bisa membaca hasil model, tapi juga menganalisis dan meningkatkannya secara strategis.
Apa Itu Confusion Matrix?
Confusion Matrix merupakan sebuah teknik yang digunakan dalam data mining dan machine learning untuk menghitung seberapa baik sebuah model dapat memprediksi label dari sebuah data. Teknik ini sering digunakan dalam evaluasi model classification yang mana model harus memprediksi label dari sebuah data berdasarkan atribut-atribut yang ada.
Confusion Matrix adalah sebuah tabel yang menggambarkan seberapa sering model memprediksi label yang benar dan salah. Setiap baris dari tabel tersebut mewakili sebuah label aktual, sedangkan setiap kolom mewakili label yang diprediksi oleh model.
Baca Juga: Belajar Data Mining: Pengertian, Metode Dan Cara Kerja
Hasil dari Confusion Matrix
Confusion Matrix membantu mengukur kinerja dimana ouput algoritma dapat berada dalam dua kategori atau lebih biasa disebut Positive atau Negative, Ya atau Tidak. Setiap tabel terdiri dari empat sel, masing-masih mewakili kombinasi unik dari nilai prediksi atau aktual. Empat hasil potensial tersebut adalah.
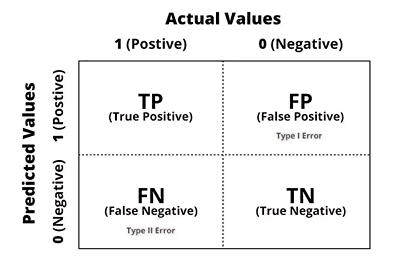
1. True Positive (TP)
Merupakan data positif yang diprediksi benar. Contohnya, pasien menderita hipertensi (class 1) dan model membuat prediksi bahwa pasien tersebut hipertensi (class 1).
2. True Negative (TN)
Merupakan data negatif yang diprediksi benar. Contoh, pasien tidak mederita hipertensi (class 2) dan model membuat prediksi bahwa pasien tersebut tidak menderita hipertensi (class 2).
3. False Positive (FP) – Type I Error
Merupakan data negatif namun diprediksi sebagai data positif. Contoh, pasien tidak menderita hipertensi (class 2) tetapi model memprediksi pasien tersebut menderita hipertensi (class 1).
4. False Negative (FN) – Type II Error
Merupakan data positif namun diprediksi sebagai data negatif. Contohnya, pasien menderita hipertensi (class 1) tetapi model memprediksi pasien tersebut tidak menderita hipertensi (class 2).
Baca Juga: Belajar Naive Bayes: Alur Algoritma, Rumus dan Contoh Perhitungan Naive Bayes
Cara Menggunakan Confusion Matrix
Berikut ini cara menghitung metode evaluasi menggunakan Confusion Matrix.
Accuracy
Accuracy merupakan metode pengujian berdasarkan tingkat kedekatan antara nilai prediksi dengan nilai aktual. Dengan mengetahui jumlah data yang diklasifikasikan secara benar maka dapat diketahui akurasi hasil prediksi.
Keterangan:
- TP (True Positive): jumlah prediksi positif yang benar
- TN (True Negative): jumlah prediksi negatif yang benar
- FP (False Positive): jumlah prediksi positif yang salah
- FN (False Negative): jumlah prediksi negatif yang salah
- Accuracy menunjukkan seberapa besar persentase prediksi model yang benar secara keseluruhan.
Precision
Precision merupakan metode pengujian dengan melakukan perbandingan jumlah informasi relevan yang didapatkan sistem dengan jumlah seluruh informasi yang terambil oleh sistem baik yang relevan maupun tidak.
Keterangan:
- Precision mengukur seberapa akurat prediksi positif dari model dibandingkan seluruh prediksi positif.
Recall
Recall merupakan metode pengujian yang membandingkan jumlah informasi relevan yang didapatkan sistem dengan jumlah seluruh informasi relevan yang ada dalam koleksi informasi (baik yang terambil atau tidak terambil oleh sistem).
Keterangan:
- Recall menunjukkan kemampuan model dalam menangkap semua instance positif yang sebenarnya.
Baca Juga: Precision dan Recall Adalah: Rumus, Contoh, dan Perbedaannya
F-Measure atau F1-Score
F-Measure atau disebut juga dengan F1-Score menggambarkan perbandingan rata-rata precision dan recall yang dibobotkan. Accuracy tepat kita gunakan sebagai acuan performansi algoritma jika data set kita memiliki jumlah data false negatif dan false positif yang sangat mendekati (symmetric). Namun jika jumlahnya tidak mendekati, maka sebaiknya kita menggunakan F1-Score.
Keterangan:
- F1-Score merupakan rata-rata harmonis dari precision dan recall, khususnya dipakai ketika distribusi kelas tidak seimbang.
Baca Juga: Memahami F1 Score untuk Evaluasi Model Klasifikasi Data
Contoh Soal Confusion Matrix
Berikut ini adalah contoh soal dari Confusion Matrix untuk model yang memprediksi label “Spam” atau “Not Spam”.
| Prediksi “Spam” | Prediksi “Not Spam” | |
|---|---|---|
| Aktual “Spam” | 50 | 10 |
| Aktual “Not Spam” | 5 | 35 |
Dari tabel di atas, dapat dilihat bahwa model tersebut memprediksi 50 email spam dengan benar, namun terdapat 10 email yang sebenarnya bukan spam tapi diprediksi sebagai spam oleh model. Sebaliknya, model tersebut memprediksi 35 email yang sebenarnya bukan spam dengan benar, namun terdapat 5 email yang sebenarnya spam tapi diprediksi sebagai bukan spam oleh model.
Untuk perhitungan akurasi, presisi dan recall sebagai berikut.
- Akurasi : (50 + 35) / (50 + 10 + 5 + 35) 85%
- Presisi “Spam” : 50 / (50 + 5) = 91%
- Recall “Spam” : 50 / (50+10) = 81%
- Presisi “Not Spam” : 35 / (35 + 10) = 78 %
- Recall “Not Spam” : 35 / (35 + 5) = 88%
Dari hasil di atas, dapat kita lihat bahwa model tersebut memiliki akurasi sebesar 85%, presisi sebesar 91% untuk memprediksi label Spam dan recall sebesar 83% untuk label Spam. Namun, untuk label Not Spam, Model tersebut hanya memiliki presisi sebesar 78% dan recall sebesar 88%.
Baca Juga: Algoritma C4.5: Pengertian, Cara kerja dan Contoh Implementasi
Mengapa Confusion Matrix Penting?
Confusion matrix adalah alat yang sangat penting dalam evaluasi kinerja model machine learning karena memberikan wawasan yang lebih mendalam tentang bagaimana model kita berkinerja daripada hanya melihat akurasi saja. Beberapa alasan mengapa confusion matrix penting adalah:
- Mengatasi Ketidakseimbangan Kelas: Dalam beberapa masalah, kelas positif dan negatif mungkin memiliki distribusi yang tidak seimbang. Confusion matrix membantu kita melihat sejauh mana model mampu mengidentifikasi kelas minoritas.
- Memahami Jenis Kesalahan: Dengan melihat false positives dan false negatives, kita dapat memahami jenis kesalahan yang dibuat oleh model. Hal ini dapat membantu dalam pengambilan tindakan yang tepat untuk meningkatkan kinerja model.
- Menyesuaikan Threshold: Dalam beberapa kasus, kita dapat menyesuaikan ambang batas (threshold) untuk mengoptimalkan kinerja model. Confusion matrix dapat membantu kita memutuskan apakah perlu mengubah threshold atau tidak.
Baca Juga: K Nearest Neighbor (KNN): Pengertian, Cara Kerja dan Penerapannya
Kesimpulan
Pada pembelajaran kita di atas dapat kita simpulkan bahwa Confusion Matrix merupakan metode evaluasi penting dalam data mining dan machine learning yang digunakan untuk mengukur performa model klasifikasi secara detail. Dengan memahami komponen seperti true positive, false positive, true negative, dan false negative, kita dapat mengetahui tidak hanya tingkat akurasi, tetapi juga jenis kesalahan yang dihasilkan oleh model.
Melalui metrik seperti accuracy, precision, recall, dan F1-score, confusion matrix membantu dalam mengambil keputusan yang lebih tepat untuk meningkatkan performa model. Oleh karena itu, memahami cara kerja confusion matrix menjadi langkah penting bagi siapa saja yang ingin mengembangkan model machine learning yang akurat dan dapat diandalkan.
Artikel ini merupakan bagian dari seri Kecerdasan Buatan KantinIT.com. Jika artikel ini bermanfaat, jangan lupa bagikan ke media sosial atau ke teman kamu.