Support Vector Machine (SVM) adalah salah satu algoritma dalam machine learning yang digunakan untuk menyelesaikan masalah klasifikasi dan regresi. Metode ini pertama kali diperkenalkan oleh Vapnik pada tahun 1992 dan sejak itu menjadi salah satu teknik paling populer dalam bidang pattern recognition. SVM dikenal karena kemampuannya dalam menghasilkan model dengan akurasi tinggi, bahkan pada dataset yang kompleks sekalipun.
Seiring dengan semakin banyaknya penerapan machine learning, muncul pertanyaan seperti apa itu Support Vector Machine, bagaimana cara kerja SVM, dan kapan algoritma ini digunakan. Memahami hal ini penting karena SVM memiliki pendekatan yang unik dalam memisahkan data menggunakan konsep hyperplane. Oleh karena itu, pada artikel ini kita akan membahas secara lengkap mulai dari pengertian, cara kerja, jenis-jenis, hingga kelebihan dan kekurangan Support Vector Machine.
Apa Itu Support Vector Machine (SVM)?
Support Vector Machine (SVM) adalah algoritma dalam machine learning berbasis supervised learning yang digunakan untuk melakukan klasifikasi dan regresi dengan cara mencari batas pemisah terbaik antar data. Algoritma ini bekerja dengan membangun sebuah garis atau bidang yang disebut hyperplane, yang berfungsi untuk memisahkan data ke dalam beberapa kelas dengan margin terbesar.
Keunggulan utama dari SVM terletak pada kemampuannya dalam menangani data berdimensi tinggi serta dataset yang kompleks, baik yang bersifat linier maupun non-linier. Dengan bantuan fungsi kernel, SVM dapat mentransformasikan data ke dalam dimensi yang lebih tinggi sehingga memungkinkan pemisahan data yang sebelumnya sulit dipisahkan secara langsung.
Metode ini sangat disukai oleh banyak orang karena algoritma ini dapat lebih menghasilkan akurasi yang signifikan dengan daya komputasi yang lebih sedikit.
Baca Juga: Belajar Kecerdasan Buatan (AI): Pengertian dan Cara Kerja Kecerdasan Buatan
Cara Kerja Support Vector Machine (SVM)
Cara kerja dari metode Support Vector Machine (SVM) dengan memetakan data ke ruang fitur berdimensi tinggi sehingga titik data dapat dikategorikan, meskipun data tidak dapat dipisahkan secara linear. Pemisah antar kategori ditermukan, kemudian data ditrasformasikan sedemikian rupa sehingga pemisah tersebut dapat digambarkan sebagai hyperplane. Setelah itu, karakteristik data baru dapat digunakan untuk memprediksi grup yang seharusnya memiliki record baru.
Contoh, perhatikan gambar berikut, dimana titik data terbagi dua kagegori berbeda.
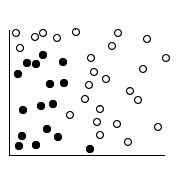
Kedua kategori tersebut dapat dipisahkan dengan kurva, seperti yang ditunjukkan pada gambar berikut.
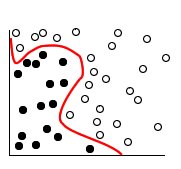
Setelah transformasi, batas antara kedua kategori tersebut dapat ditentukan oleh hyperplane, seperti ditunjukan pada gambar berikut.
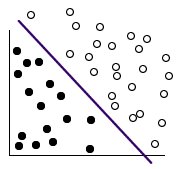
Hyperplane adalah garis dengan margin terbesar untuk kedua group. Terkadang ada yang menyebutnya garis di atas garis keputusan, tetapi istilah matematika yang benar adalah hyperplane, karena dalam dimensi lebih tinggi dari dua dan tidak akan menjadi garis lagi.
Fungsi matematika yang digunakan untuk transformasi dikenal sebagai fungsi kernel. SVM di IBM® SPSS® modeler mendukung jenis kernel berikut:
- Linier
- Polinominal
- Fungsi Basis Radial (RBF)
- Sigmoid
Fungsi kernel linier direkomendasikan ketika pemisahan data secara linier mudah dilakukkan. Dalam kasus lain, salah satu fungsi lain harus digunakan. Kamu harus mencoba dengan fungsi yang berbeda untuk mendapatkan model terbaik di setiap kasus, karena masing-masing menggunakan algoritma dan parameter yang berbeda.
Baca Juga: Radial Basis Function (RBF): Konsep, Rumus, dan Contoh
Jenis-Jenis Support Vector Machine (SVM)
SVM terbagi menjadi dua jenis yaitu.
1. SVM Data Linier
Digunakan untuk data yang dapat dipisahkan secara linier, berarti jika sebuah dataset dapat diklasifikasikan menjadi dua kelas dengan menggunakkan sebuah garis lurus tunggal disebut linier dan klasifikasinya disebut sebagai Linear SVM Classifier.
2. SVM Data Non-Linier
Digunakan untuk data yang dapat dipisahkan secara non-linier, berarti jika sebuah dataset tidak dapat diklasifikasi menggunakan garis lurus disebut data non-linier dan klasifikasinya disebut sebagai Non-Linier SVM Classifier.
Perbedaan Data Linier dengan Non-Linier
Data linier dapat mengklasifikasikan data dengan pengklasifikasi linier. Pengklasifikasi linier membuat keputusan klasifikasinya berdasarkan kombinasi linier dari karakteristik.
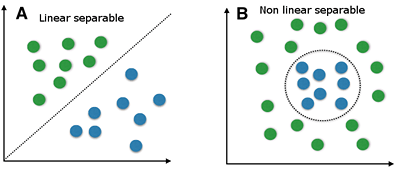
Pada gambar A kita dapat memisahkan label target secara linier dengan garis (seperti Support Vector Machines melakukan klasifikasi dengan garis keputusan). Pengklasifikasi linier dapat melakukan ini dengan kombinasi karakteristik linier. kita dapat menggunakan misalnya SVM untuk membuat model, tetapi kita juga dapat menggunakan banyak metode klasifikasi linier lainya seperti klasifikasi kuadrat.
Pada gambar B kita dapat memisahkan label target secara linier. Data lebih kompleks dibagi, oleh karena itu kita bisa begitu saja menggunakan metode klasifikasi linier. Utungnya SVM dapat melakukan keduanya, klasifikasi linier dan non-linier.
Baca Juga: Supervised Learning Adalah: Pengertian, Konsep dan Contoh
Kelebihan dan Kekurangan Support Vector Machine (SVM)
Support Vector Machine seperti metode pada umumnya yang memiliki kelebihan dan kekurangan, adapun kelebihan dan kekurangannya sebagai berikut.
Kelebihan Support Vector Machine
- Efektif dalam ruang dimensi tinggi.
- Masih efektif dalam kasus di mana jumlah dimensi lebih besar dari jumlah sampel.
- Menggunakan subset titik pelatihan dalam fungsi keputusan (disebut vektor dukungan), sehingga menghemat memori.
- Serbaguna, fungsi kernel yang berbeda dapat dituntukan untuk fungsi keputusan. Kernel umum disediakan, tetapi juga memungkinkan untuk menentukan kernel buatan.
Kekurangan Support Vector Machine
- Jika jumlah fitur jauh lebih banyak daripada jumlah sampel, hindari pemilihan fungsi kernel yang berlebihan dan istilah regularisasi sangat penting.
- SVM tidak secara lansung memberikan perkiraan probabilitas, ini dihitung menggunakan validasi silang lima kali lipat yang mahal.
Baca Juga: Algoritma Adalah: Jenis, Fungsi dan Contoh
Kesimpulan
Dari pembelajaran kita di atas dapat kita simpulkan bahwa Support Vector Machine (SVM) merupakan salah satu algoritma dalam machine learning yang digunakan untuk menyelesaikan masalah klasifikasi dan regresi dengan memanfaatkan konsep hyperplane sebagai pemisah data. Dengan kemampuannya dalam menangani data berdimensi tinggi serta dukungan fungsi kernel, SVM menjadi salah satu metode yang sangat powerful dalam analisis data.
Pemahaman tentang pengertian SVM, cara kerja, jenis-jenis, serta kelebihan dan kekurangannya sangat penting bagi siapa saja yang ingin mendalami data science. Dengan penerapan yang tepat, SVM dapat digunakan dalam berbagai bidang seperti klasifikasi teks, deteksi spam, hingga pengenalan pola dalam data kompleks.
Artikel ini merupakan bagian dari seri Kecerdasan Buatan KantinIT.com. Jika artikel ini bermanfaat, jangan lupa bagikan ke media sosial atau ke teman kamu.