Perkembangan teknologi Computer Vision dalam satu dekade terakhir berjalan sangat cepat. Jika sebelumnya model berbasis Convolutional Neural Network (CNN) menjadi tulang punggung hampir semua tugas pengolahan citra, kini muncul pendekatan baru yang mengubah cara mesin “melihat” gambar. Salah satu pendekatan yang paling banyak dibicarakan adalah Vision Transformer (ViT). Model ini membawa konsep Transformer yang sebelumnya sukses besar di Natural Language Processing (NLP) ke ranah visual.
Menariknya, Vision Transformer tidak menggunakan operasi konvolusi seperti CNN. Sebaliknya, ViT memperlakukan gambar seperti sebuah rangkaian data, mirip dengan kalimat dalam NLP. Pendekatan ini membuka perspektif baru dalam memahami hubungan global antar bagian gambar. Buat kamu yang berkecimpung di dunia IT, data science, atau riset akademik, memahami Vision Transformer bukan lagi sekadar opsi, tetapi sudah menjadi kebutuhan.
Apa Itu Vision Transformer (ViT)?
Vision Transformer (ViT) adalah arsitektur deep learning yang dirancang untuk memproses data visual menggunakan mekanisme Transformer. Secara sederhana, ViT mengadaptasi model Transformer standar yang awalnya dibuat untuk teks agar bisa bekerja dengan gambar. Pendekatan ini pertama kali diperkenalkan oleh Google Research dalam paper berjudul “An Image is Worth 16×16 Words”.
Berbeda dengan CNN yang mengekstrak fitur gambar secara lokal menggunakan kernel konvolusi, ViT memandang gambar sebagai kumpulan potongan kecil yang disebut patch. Setiap patch diperlakukan seperti “token” pada teks. Token-token ini kemudian diproses menggunakan mekanisme self-attention untuk menangkap hubungan antar bagian gambar secara global.
Dalam ekosistem deep learning, Vision Transformer menempati posisi unik. Ia tidak sepenuhnya menggantikan CNN, tetapi menawarkan alternatif yang sangat kuat, terutama ketika digunakan pada dataset berukuran besar. Banyak penelitian menunjukkan bahwa ViT mampu menyaingi bahkan melampaui performa CNN dalam berbagai tugas Computer Vision, asalkan dilatih dengan data yang cukup.
Konsep Dasar Transformer
Untuk memahami Vision Transformer, kamu perlu memahami konsep dasar Transformer terlebih dahulu. Transformer adalah arsitektur neural network yang diperkenalkan pada tahun 2017 dan menjadi fondasi model-model besar seperti BERT dan GPT. Inti dari Transformer terletak pada mekanisme self-attention.
Self-attention memungkinkan model untuk menilai seberapa penting setiap elemen input terhadap elemen lainnya. Dalam konteks teks, ini berarti satu kata bisa “memperhatikan” kata lain dalam satu kalimat. Dalam konteks gambar, satu patch bisa memperhatikan patch lain, bahkan yang lokasinya berjauhan.
Transformer terdiri dari beberapa komponen utama, seperti encoder, multi-head attention, feed-forward network, residual connection, dan layer normalization. Vision Transformer memanfaatkan bagian encoder dari Transformer karena tugas utamanya adalah memahami representasi input, bukan menghasilkan urutan output seperti pada machine translation.
Cara Kerja Vision Transformer
Cara kerja Vision Transformer bisa dibilang cukup berbeda dibanding CNN. Alih-alih melakukan konvolusi secara bertahap, ViT memulai prosesnya dengan membagi gambar menjadi beberapa bagian kecil.
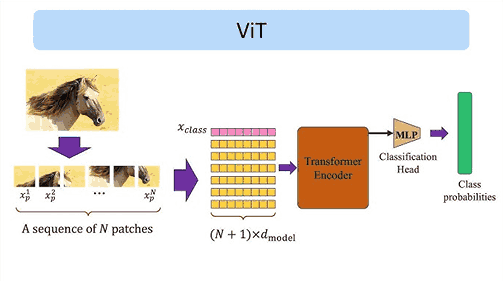
Secara umum, alur kerja Vision Transformer adalah sebagai berikut:
- Gambar dibagi menjadi patch kecil
Sebuah gambar dengan ukuran tertentu, misalnya 224×224 piksel, dibagi menjadi patch berukuran tetap, misalnya 16×16 piksel. Proses ini menghasilkan sejumlah patch yang masing-masing merepresentasikan bagian kecil dari gambar. - Patch diubah menjadi vektor (embedding)
Setiap patch diratakan (flatten) lalu dilewatkan ke linear projection untuk menghasilkan vektor embedding. Pada tahap ini, gambar sudah berubah menjadi sekumpulan vektor numerik. - Penambahan positional embedding
Karena Transformer tidak memahami urutan secara alami, positional embedding ditambahkan agar model tahu posisi relatif setiap patch dalam gambar. - Diproses oleh encoder Transformer
Seluruh embedding patch dimasukkan ke encoder Transformer yang terdiri dari beberapa layer self-attention dan feed-forward network. - Klasifikasi output
Output akhir dari encoder digunakan untuk melakukan tugas tertentu, seperti klasifikasi gambar.
Pendekatan ini memungkinkan ViT menangkap hubungan global sejak awal, bukan secara bertahap seperti CNN.
Arsitektur Vision Transformer (ViT)
Arsitektur Vision Transformer secara garis besar terdiri dari tiga bagian utama yaitu:
- Patch Embedding
Patch embedding bertugas mengubah gambar mentah menjadi representasi numerik yang bisa diproses oleh Transformer. Encoder Transformer berfungsi sebagai “otak” utama yang mempelajari hubungan antar patch. Sementara itu, classification head bertanggung jawab menghasilkan output akhir sesuai tugas yang diinginkan. - Encoder Transformer
Di dalam encoder, terdapat beberapa blok yang masing-masing berisi multi-head self-attention dan feed-forward network. Residual connection dan layer normalization digunakan untuk menjaga stabilitas training, terutama ketika jumlah layer bertambah banyak. - Classification Head
Arsitektur ini membuat ViT sangat fleksibel. Kamu bisa menyesuaikan jumlah layer, ukuran embedding, dan jumlah head attention sesuai kebutuhan. Fleksibilitas inilah yang membuat Vision Transformer banyak digunakan dalam riset dan pengembangan lanjutan.
Vision Transformer vs Convolutional Neural Network (CNN)
Perbandingan antara Vision Transformer dan CNN sering menjadi topik hangat di kalangan peneliti dan praktisi. Keduanya memiliki pendekatan yang sangat berbeda dalam memproses gambar.
Berikut tabel perbandingan singkat antara ViT dan CNN:
| Aspek | Vision Transformer (ViT) | Convolutional Neural Network (CNN) |
|---|---|---|
| Pendekatan | Global (self-attention) | Lokal (kernel konvolusi) |
| Pemahaman konteks | Sangat kuat | Bertahap |
| Kebutuhan data | Sangat besar | Relatif lebih kecil |
| Skalabilitas | Tinggi | Terbatas |
| Interpretabilitas | Lebih mudah via attention | Lebih sulit |
CNN unggul pada dataset kecil hingga menengah, sedangkan ViT menunjukkan performa luar biasa ketika dilatih dengan data besar. Oleh karena itu, pemilihan antara ViT dan CNN sangat bergantung pada konteks penggunaan dan ketersediaan data.
Kelebihan Vision Transformer
Vision Transformer memiliki sejumlah kelebihan yang membuatnya menarik bagi komunitas Computer Vision.
- Pemahaman konteks global
ViT mampu memahami hubungan antar bagian gambar secara menyeluruh sejak awal pemrosesan, bukan secara bertahap seperti CNN. Hal ini sangat membantu dalam tugas yang membutuhkan pemahaman konteks luas. - Skalabilitas tinggi
Semakin besar dataset dan model, performa ViT cenderung semakin baik. Ini membuatnya cocok untuk aplikasi berskala besar. - Arsitektur fleksibel
ViT mudah dikombinasikan dengan arsitektur lain dan dimodifikasi untuk berbagai tugas Computer Vision.
Kelebihan-kelebihan ini menjadikan ViT sebagai salah satu model paling berpengaruh dalam riset Computer Vision modern.
Kekurangan Vision Transformer
Di balik kelebihannya, Vision Transformer juga memiliki beberapa kekurangan yang perlu diperhatikan.
- Membutuhkan data training besar
Tanpa data yang cukup, performa ViT bisa kalah dari CNN. Ini menjadi tantangan bagi peneliti dengan keterbatasan data. - Biaya komputasi tinggi
Mekanisme self-attention memiliki kompleksitas yang tinggi, sehingga membutuhkan resource komputasi yang besar. - Kurang efisien untuk perangkat terbatas
Untuk deployment di edge device atau mobile, ViT masih memerlukan optimasi tambahan.
Memahami kekurangan ini penting agar kamu bisa memilih model yang tepat sesuai kebutuhan proyek.
Penerapan Vision Transformer di Dunia Nyata
Vision Transformer telah digunakan dalam berbagai aplikasi nyata. Dalam image classification, ViT mampu mencapai akurasi tinggi pada dataset besar seperti ImageNet. Di bidang medical imaging, ViT membantu mendeteksi penyakit dari citra medis dengan presisi tinggi.
Selain itu, ViT juga digunakan dalam object detection, video analysis, dan sistem autonomous. Kemampuannya memahami konteks global membuatnya sangat cocok untuk aplikasi kompleks yang melibatkan banyak objek dalam satu gambar.
Kesimpulan
Pada pembahasan kita di atas dapat kita simpulkan bahwa Vision Transformer (ViT) membawa perubahan besar dalam dunia Computer Vision dengan memperkenalkan pendekatan berbasis Transformer yang sebelumnya dominan di NLP. Dengan memproses gambar sebagai kumpulan patch dan memanfaatkan mekanisme self-attention, ViT mampu memahami hubungan global antar bagian gambar secara lebih efektif dibanding pendekatan tradisional berbasis CNN.
Meskipun memiliki tantangan seperti kebutuhan data besar dan biaya komputasi tinggi, Vision Transformer tetap menjadi pilihan menarik bagi peneliti, programmer, dan praktisi data science. Dengan terus berkembangnya varian dan teknik optimasi, ViT berpotensi menjadi fondasi utama bagi generasi berikutnya dari sistem Computer Vision.
Artikel ini merupakan bagian dari seri artikel belajar Kecerdasan Buatan dan jika ada ide topik yang mau kami bahas silahkan komen di bawah ya..