Pada era digital yang semakin berkembang, pemodelan dan analisis data menjadi sangat penting dalam berbagai bidang, termasuk ilmu data dan kecerdasan buatan. Salah satu metode yang sering digunakan dalam pengembangan model adalah cross validation.
Dalam artikel ini, kita akan mempelajari konsep cross validation, manfaatnya dan bagaimana mengimplementasikannya dalam proyek machine learning. Yukk simak!
Apa Itu Cross Validation?

Cross validation adalah teknik dalam machine learning yang digunakan untuk mengevaluasi performa model dan meminimalkan risiko overfitting. Dalam teknik ini, data yang ada dibagi menjadi dua bagian, yaitu data training dan data testing. Data training digunakan untuk melatih model, sedangkan data testing digunakan untuk menguji seberapa baik model tersebut bekerja.
Pentingnya Cross Validation dalam Machine Learning
Cross validation sangat penting dalam Machine Learning karena memungkinkan kita untuk menghindari masalah overfitting dan underfitting. Overfitting terjadi ketika model terlalu kompleks dan “menghafal” data pelatihan, sehingga tidak mampu menggeneralisasi dengan baik pada data baru. Sementara itu, underfitting terjadi ketika model terlalu sederhana dan gagal menangkap pola yang ada dalam data.
Dengan menggunakan teknik ini, kita dapat memastikan bahwa model kita tidak hanya mempelajari data pelatihan secara spesifik, tetapi juga mampu menggeneralisasi dengan baik pada data baru. Hal ini penting untuk mendapatkan model yang dapat digunakan dengan efektif dalam berbagai situasi.
Jenis-Jenis Cross Validation
Ada beberapa metode yang umum digunakan. Beberapa di antaranya adalah:
1. Holdout Cross Validation
Metode Holdout adalah metode yang paling sederhana. Pada metode ini, dataset dibagi menjadi dua bagian secara acak: data pelatihan dan data pengujian. Biasanya, sekitar 70-80% data digunakan untuk pelatihan model, sementara 20-30% sisanya digunakan untuk pengujian. Model dilatih menggunakan data pelatihan dan dievaluasi menggunakan data pengujian.
2. K-Fold Cross Validation
K-Fold cross validation adalah salah satu metode yang paling umum digunakan. Pada metode ini, dataset dibagi menjadi K bagian atau “fold”. Setiap fold bergantian digunakan sebagai data pengujian, sementara fold yang lain digunakan sebagai data pelatihan. Model dilatih dan dievaluasi K kali, di mana setiap fold digunakan sebagai data pengujian satu kali. Hasil evaluasi pada setiap iterasi digunakan untuk menghitung rata-rata kinerja model secara keseluruhan.
3. Stratified K-Fold Cross Validation
Metode Stratified K-Fold adalah variasi dari K-Fold yang menjaga distribusi kelas pada setiap fold agar tetap seimbang. Metode ini berguna jika dataset memiliki ketidakseimbangan yang signifikan antara kelas-kelas yang ada. Metode ini memastikan bahwa setiap fold mencerminkan distribusi kelas secara proporsional.
4. Leave-One-Out Cross Validation
Leave-One-Out cross validation (LOOCV) adalah metode yang ekstensif. Pada metode ini, setiap sampel dalam dataset digunakan sebagai data pengujian secara bergantian, sementara sampel yang lain digunakan sebagai data pelatihan. Jika dataset memiliki N sampel, model dilatih dan dievaluasi sebanyak N kali. Metode ini cocok untuk dataset dengan jumlah sampel yang terbatas, tetapi memerlukan waktu komputasi yang lebih tinggi.
5. Repeated K-Fold Cross Validation
Metode Repeated K-Fold adalah variasi dari K-Fold yang melibatkan pengulangan K-Fold secara keseluruhan. Metode ini berguna untuk memperoleh hasil yang lebih stabil dan dapat diandalkan. Dengan mengulangi K-Fold beberapa kali, kita dapat menghitung rata-rata kinerja model dari berbagai kombinasi pembagian data.
Langkah-Langkah Implementasi Cross Validation
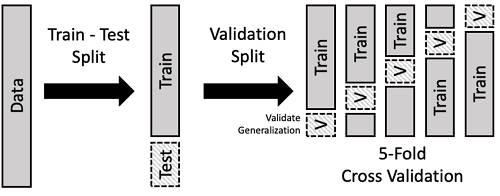
Berikut adalah langkah-langkah umum untuk mengimplementasikan teknik ini dalam proyek machine learning:
1. Pisahkan Data
Pertama, kita perlu membagi data menjadi fitur (features) dan label (target). Selanjutnya, dataset dibagi menjadi bagian-bagian (folds) yang sesuai dengan metode yang dipilih.
2. Latih dan Uji Model
Selanjutnya, kita melatih model menggunakan data latih dan menguji performanya pada data uji. Ini dilakukan untuk setiap iterasi.
3. Evaluasi dan Pemilihan Model Terbaik
Setelah selesai melakukan cross validation, kita dapat menggabungkan hasil dari setiap iterasi untuk mengevaluasi performa model secara keseluruhan. Berdasarkan metrik evaluasi yang relevan, kita dapat memilih model terbaik yang akan digunakan untuk prediksi data baru.
Contoh Penggunaan Cross Validation
Misalnya, kita ingin membangun model untuk memprediksi apakah seorang siswa akan lulus ujian berdasarkan waktu belajar dan tingkat kehadiran. Kita dapat menggunakan teknik ini untuk membagi data menjadi data training dan data testing, membangun model dan menguji performa model menggunakan data testing. Dengan teknik ini, kita dapat mendapatkan perkiraan yang lebih akurat tentang seberapa baik model kita dapat memprediksi kelulusan siswa.
Kelebihan Cross Validation
- Menghindari overfitting: Membantu menghindari overfitting, yaitu kondisi di mana model terlalu spesifik untuk data pelatihan tetapi tidak dapat digeneralisasi dengan baik pada data baru. Dengan menggunakan data validasi yang terpisah, kita dapat memperoleh perkiraan yang lebih akurat tentang performa model pada data baru.
- Memperkirakan performa model: Dapat memperoleh perkiraan yang lebih akurat tentang seberapa baik model kita akan berkinerja pada data yang belum pernah dilihat sebelumnya. Ini membantu dalam pengambilan keputusan yang lebih baik tentang apakah model tersebut layak digunakan atau tidak.
- Optimasi parameter: Untuk menguji berbagai kombinasi parameter dan memilih yang paling baik berdasarkan performa model pada data validasi. Dengan demikian, kita dapat mengoptimalkan parameter model untuk mencapai performa yang lebih baik.
Kekurangan Cross Validation
- Komputasi yang intensif: Dapat memakan waktu dan sumber daya komputasi yang signifikan, terutama jika kita memiliki dataset yang besar atau menggunakan metode yang intensif seperti Leave-One-Out Cross Validation (LOOCV). Hal ini dapat menjadi kendala jika kita memiliki keterbatasan waktu atau sumber daya komputasi.
- Ketergantungan pada pembagian data: Hasil dari teknik ini dapat bervariasi tergantung pada bagaimana data dibagi menjadi fold atau kelompok. Jika pembagian fold tidak mewakili variasi data dengan baik, hasil evaluasi dapat menjadi bias. Oleh karena itu, penting untuk memperhatikan pembagian data dengan cermat.
Kesimpulan
Cross validation adalah teknik penting dalam pengembangan model machine learning yang akurat dan dapat diandalkan. Dengan membagi dataset menjadi bagian-bagian dan menguji model pada data yang berbeda-beda, kita dapat menghindari overfitting dan underfitting, serta mendapatkan estimasi kinerja model yang lebih akurat. Dengan memahami konsep dan mengimplementasikannya dengan baik, kita dapat mengoptimalkan performa model machine learning kita.
Artikel ini merupakan bagian dari seri artikel belajar Kecerdasan Buatan dan jika ada ide topik yang mau kita bahas silahkan komen di bawah ya.